promptlayer_client.run– zero-setup SDK sugar- Webhook-driven caching – maintain local cache of prompt templates
- GitOps with Webhooks – keep Git as your source of truth with bi-directional sync
- Managed Workflows – let PromptLayer orchestrate everything server-side
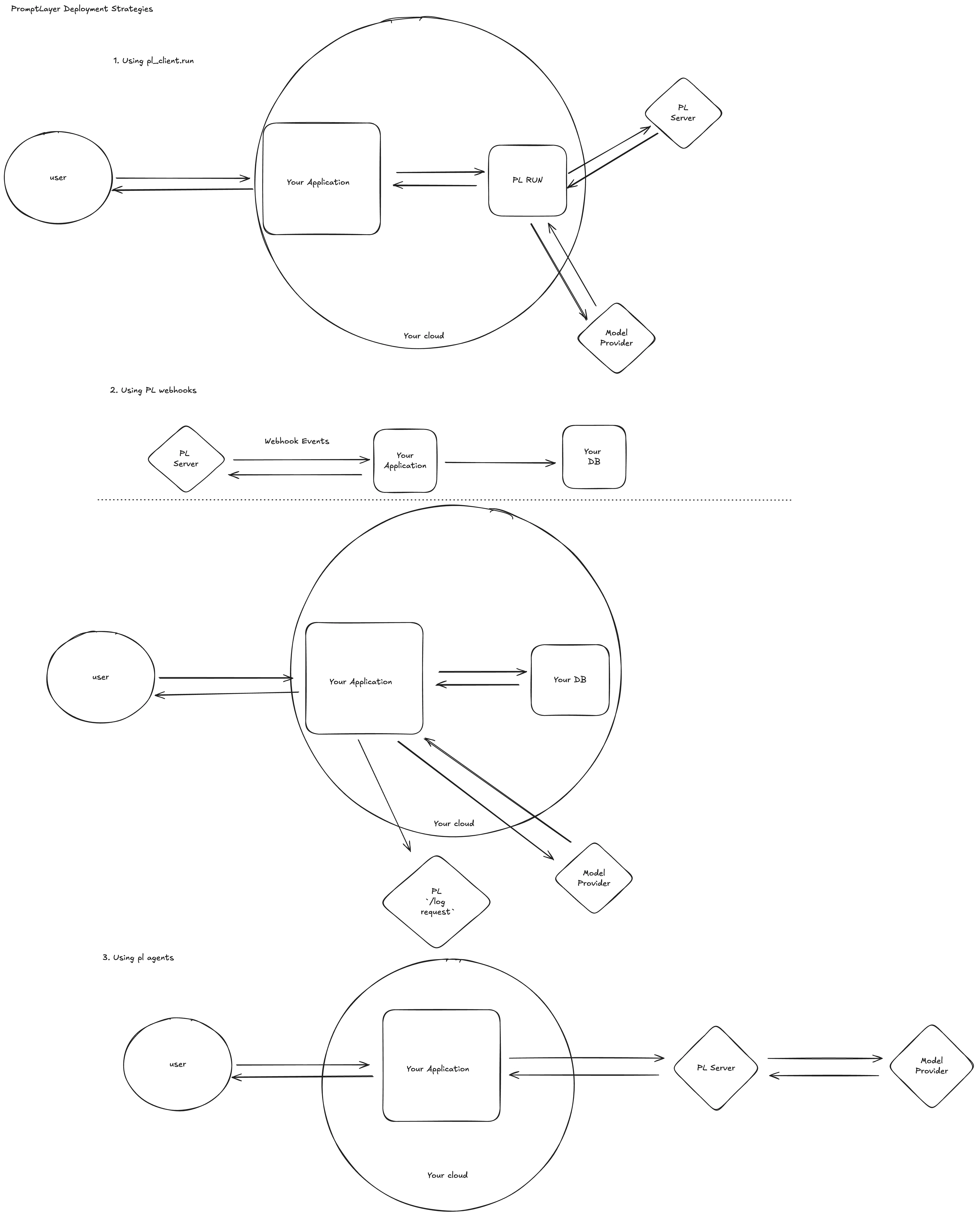
Use promptlayer_client.run (quickest path)
When every millisecond of developer time counts, call promptlayer_client.run() directly from your application code.
- Fetch latest prompt – We pull the template (by version or release label) from PromptLayer.
- Execute – The SDK sends the populated prompt to OpenAI, Anthropic, Gemini, etc.
- Log – The raw request/response pair is saved back to PromptLayer.---
Cache prompts with Webhooks
Eliminate the extra round‑trip by replicating prompts into your own cache or database. PromptLayer keeps that cache fresh through webhook events—no polling required.Step‑by‑step
- Subscribe to webhooks in the UI
- Maintain a local cache
- Serve traffic
💡 Tip: Most teams push the track_to_promptlayer onto a Redis or SQS queue so as to not block on the logging of a request.Read the full guide: PromptLayer Webhooks ↗
GitOps with Webhooks
For teams that want Git as the source of truth for prompts, webhooks enable a full bi-directional sync between PromptLayer and your repository. This is the recommended pattern for teams with existing CI/CD pipelines (GitHub Actions, GitLab CI, etc.) that want prompt changes to go through the same review and deploy process as code changes.Change starts on PromptLayer
When someone edits a prompt or approves a release label in PromptLayer, a webhook fires to your system. Your webhook handler creates a merge request (or pull request) in your repo with the updated prompt. From there, your normal CI/CD pipeline takes over — code review, automated evals, deploy. Key webhook events for this flow:prompt_template_version_created– a new version of a prompt was savedprompt_template_label_moved– a release label (e.g.prod) was moved to a new versionprompt_template_label_change_approved– a protected release label change was approved
Change starts in code
When an engineer updates a prompt directly in the repo, your CI/CD pipeline can publish it back to PromptLayer using the REST API or SDK. This keeps PromptLayer in sync without any manual steps.Closing the loop with eval results
If your CI/CD pipeline runs evaluations as part of the deploy process, you can push those results back to PromptLayer so everything is visible in one place. This means your team doesn’t lose observability just because the deploy happened outside of PromptLayer.💡 Tip – Combine this with protected release labels and approval workflows so that a prompt change in PromptLayer requires approval before the webhook fires and the MR is created.
Run fully-managed Workflows
For complex pipelines requiring orchestration, use PromptLayer’s managed workflow infrastructure.How it works
- Define multi-step workflows in PromptLayer’s Workflow Builder
- Trigger workflow execution via API
- Monitor execution on PromptLayer servers
- Receive results via webhook or polling
Implementation
Which pattern should I pick?
Further reading 📚
- Quickstart – Your first prompt
- Webhooks – Events & signature verification
- Workflows – Concepts & versioning
- CI for prompts – Continuous Integration guide
✉️ Need a hand? Ping us in Discord or email hello@promptlayer.com—happy to chat architecture!