Primary Types
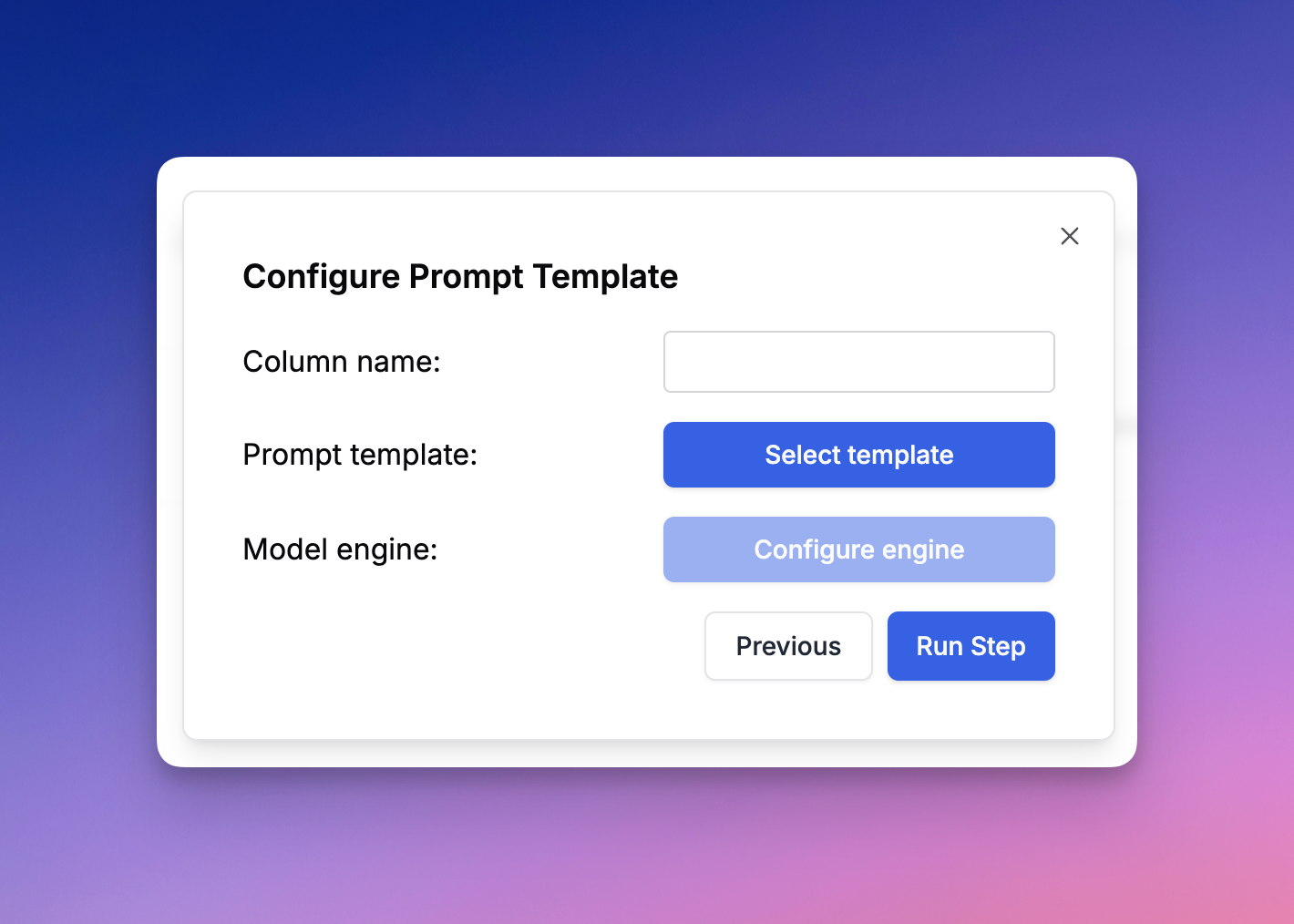
Prompt Template
The Prompt Template evaluation type allows you to execute a prompt template from the Prompt Registry. You have the flexibility to select the latest version, a specific label, or a particular version of the prompt template. You also have the ability to assign the input variables based on available inputs from the dataset or other columns. You can override the model parameters that are set in the Prompt Registry. This functionality is particularly useful for testing a prompt template within a larger evaluation pipeline, comparing different model parameters, or implementing an “LLM as a judge” prompt template.Custom API Endpoint
The Custom API Endpoint enables you to set up a webhook that our system will call (POST) with all the columns to the left of the API endpoint when that cell is executed. As cells are processed sequentially, we will call this endpoint with the columns in the payload, and the returned result will be displayed. This feature allows for extensive customization to accommodate specific use cases and integrate with external systems or custom evaluators.MCP
The MCP Action allows you to run functions on a remote MCP server. Simply plug in your server URL and auth, select your function and you will be able to call your function with inputs mapped from other cells. For more information about MCP check out the official MCP docs.Human Input
The Human Input evaluation type allows the addition of either numeric or text input where an evaluator can provide feedback via a slider or a text box. This input can then be utilized in subsequent columns in the evaluation pipeline, allowing for the incorporation of human judgment.Code Execution
The Code Execution evaluation type allows you to write and execute code for each row in your dataset. You can access the data through thedata variable and return the cell value. Note that stdout will be ignored. There is a 6 minute timeout for code execution.
Code example to return a list of the names of each column:
Coding Agent
The Coding Agent evaluation type uses an AI coding agent (such as Claude Code) in a secure, sandboxed environment for each row in your dataset. Instead of writing code directly, you provide natural language instructions describing what you want to accomplish, and the AI coding agent handles the implementation. How it works: You provide a natural language prompt describing the task you want to accomplish. The coding agent executes in an isolated sandbox with access to:- variables.json - Automatically injected file containing all column values from previous cells in that row
- File attachments - Any files you upload (CSV, JSON, text files, etc.) are available in the sandbox
- Network access - Can make API calls and fetch external data
- Data transformation: “Parse the JSON response from the API column and extract all user emails into a comma-separated list”
- File processing: “Read the attached sales_data.csv and calculate the total revenue for products in the ‘Electronics’ category”
- API integration: “Use the api_key from variables.json to fetch user details from https://api.example.com/users/{user_id} and return their account status”
Conversation Simulator
The Conversation Simulator evaluation type automates the back-and-forth between your AI agent and simulated users to test conversational AI performance. This is particularly useful for evaluating multi-turn conversations where context maintenance, goal achievement, and user interaction patterns are critical. When setting up the conversation simulator:- Select your AI agent prompt template from the Prompt Registry
- Pass in user details or context variables from your dataset
- Define a test persona that challenges your AI with specific behaviors or constraints
- User Goes First: By default, the AI agent initiates the conversation. You can enable this setting to have the simulated user start the conversation instead.
- Conversation Samples: You can provide sample conversations to help guide the simulated user’s responses. These samples help maintain consistent voice and interaction patterns, ensuring the simulated user behaves realistically and consistently with your expected user base.
- Completion Guidance: Define specific conditions for when the conversation should be considered complete. This is useful for specifying end conditions like tool calls, confirmation messages, or goal achievement (e.g., “End when the assistant calls the submit_order tool” or “Complete when the user confirms their booking”). You can provide this as a static value or pull it from a dataset column for varied test scenarios.
Simple Evals
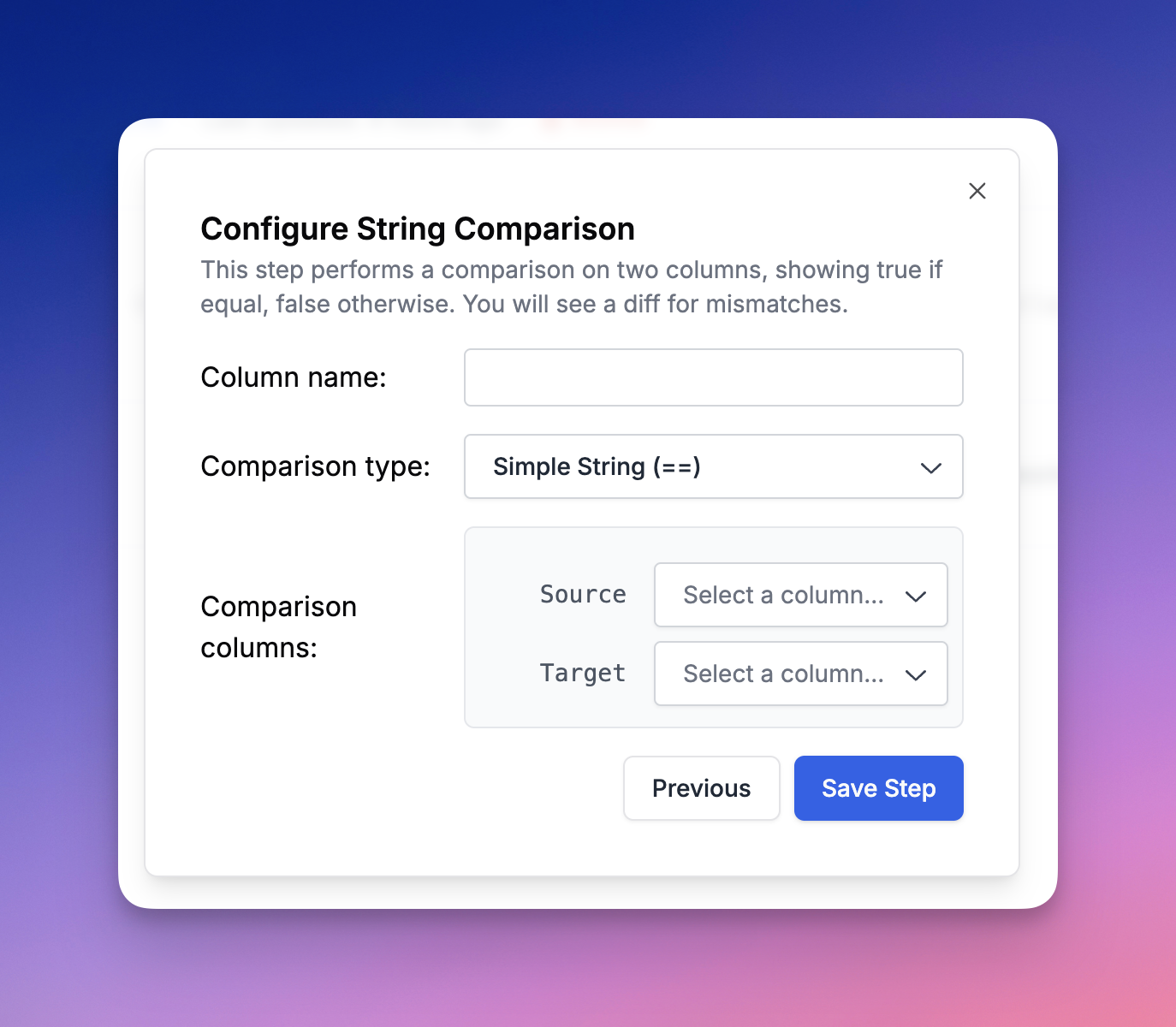
Equality Comparison
Equality Comparison allows you to compare two different columns as strings. It provides a visual diff if there is a difference between the columns. Note that the diff is not used when calculating the score in that column and the column will be treated as a boolean for the purposes of a score. If there is no difference, it this column return true.Contains Value
The Contains evaluation type enables you to search for a substring within a column. For instance, you could search for a specific word or phrase within each cell in the column. It is using the pythonin operator to check if the substring is in the cell and is case insensitive.
Regex Match
The Regex Match evaluation type allows you to define a regular expression pattern to search within the column. This provides powerful pattern matching capabilities for complex text analysis tasks.Absolute Numeric Distance
The Absolute Numeric Distance evaluation type allows you to select two different columns and output the absolute distance between their numeric values in a new column. Both source columns must contain numeric values.LLM Evals
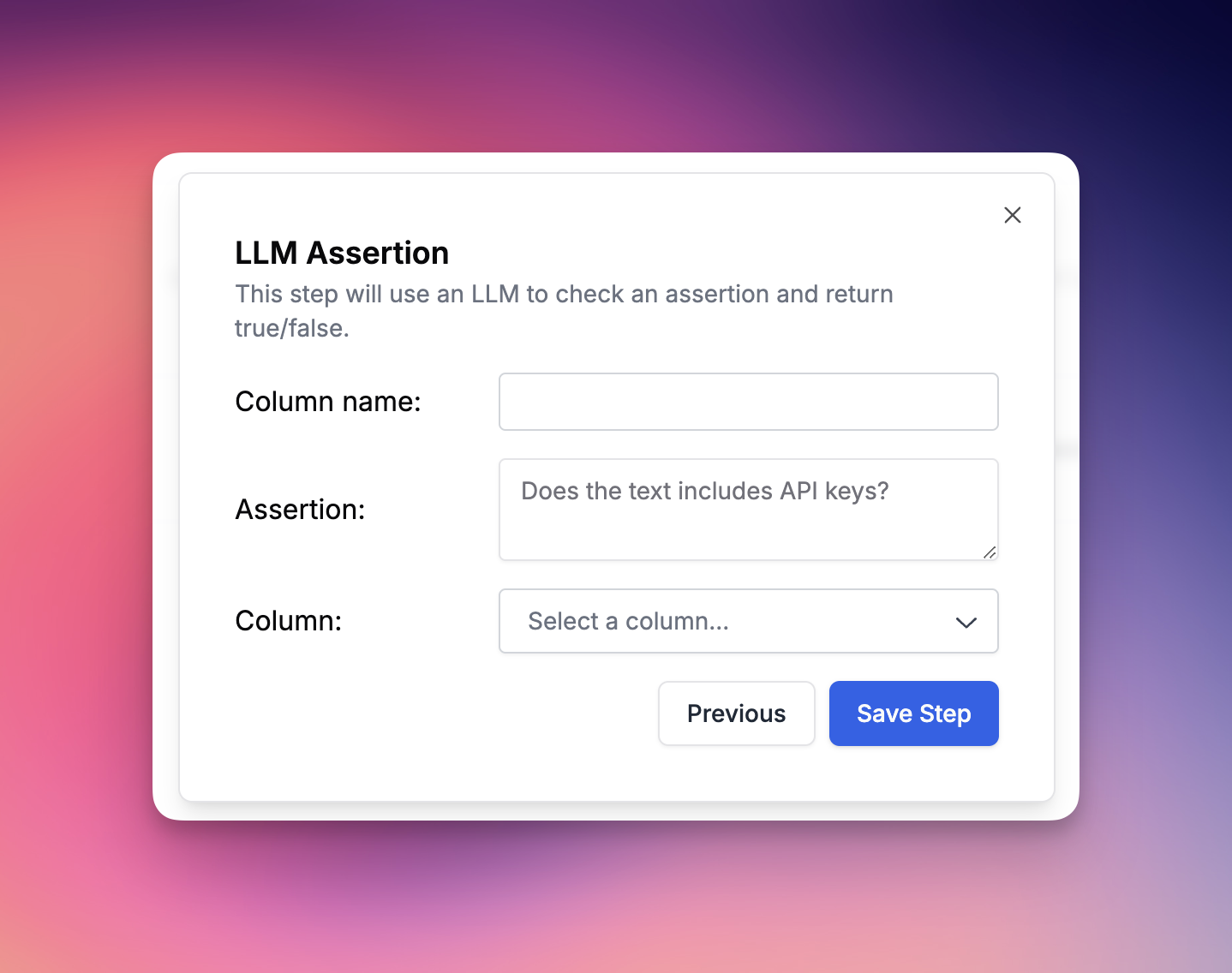
Run LLM Assertion
The LLM Assertion evaluation type enables you to run an assertion on a column using natural language prompts. You can create prompts such as “Does this contain an API key?”, “Is this sensitive content?”, or “Is this in English?”. Our system uses a backend prompt template that processes your assertion and returns either true or false. Assertions should be framed as questions.Using Template Variables
You can use template variables in your assertions to reference values from other dataset columns. This allows you to create dynamic assertions that adapt based on your data. Use f-string style syntax with single curly braces:{variable_name}
Example assertions with variables:
"Is the response written in {language}?""Does the output discuss {topic}?""Is the tone {expected_tone}?"
"Is the response written in {language}?" and you have a column called target_language, you would map language → target_language.
All variables used in assertions must be mapped to a column. If a variable is not mapped, the evaluation will fail with an error indicating which variable mapping is missing.
Multiple Assertions
You can add multiple assertions to evaluate different criteria on the same data source. Each assertion is evaluated independently and returns its own true/false result.AI Data Extract
The AI Data Extract evaluation type uses AI/LLM to extract specific information from data sources. You can describe what you want to extract using natural language queries, whether the content is JSON, XML, or just unstructured text. Example queries:- “Extract the product name”
- “Find the customer’s email address”
- “Get all mentioned dates”
- “Extract the total price including tax”
Cosine Similarity
Cosine Similarity allows you to compare the vector distance between two columns. The system takes the two columns you supply, converts them into strings, and then embeds them using OpenAI’s embedding vectors. It then calculates the cosine similarity, resulting in a number between 0 and 1. This metric is useful for understanding how semantically similar two bodies of text are, which can be valuable in assessing topic adherence or content similarity.Helper Functions
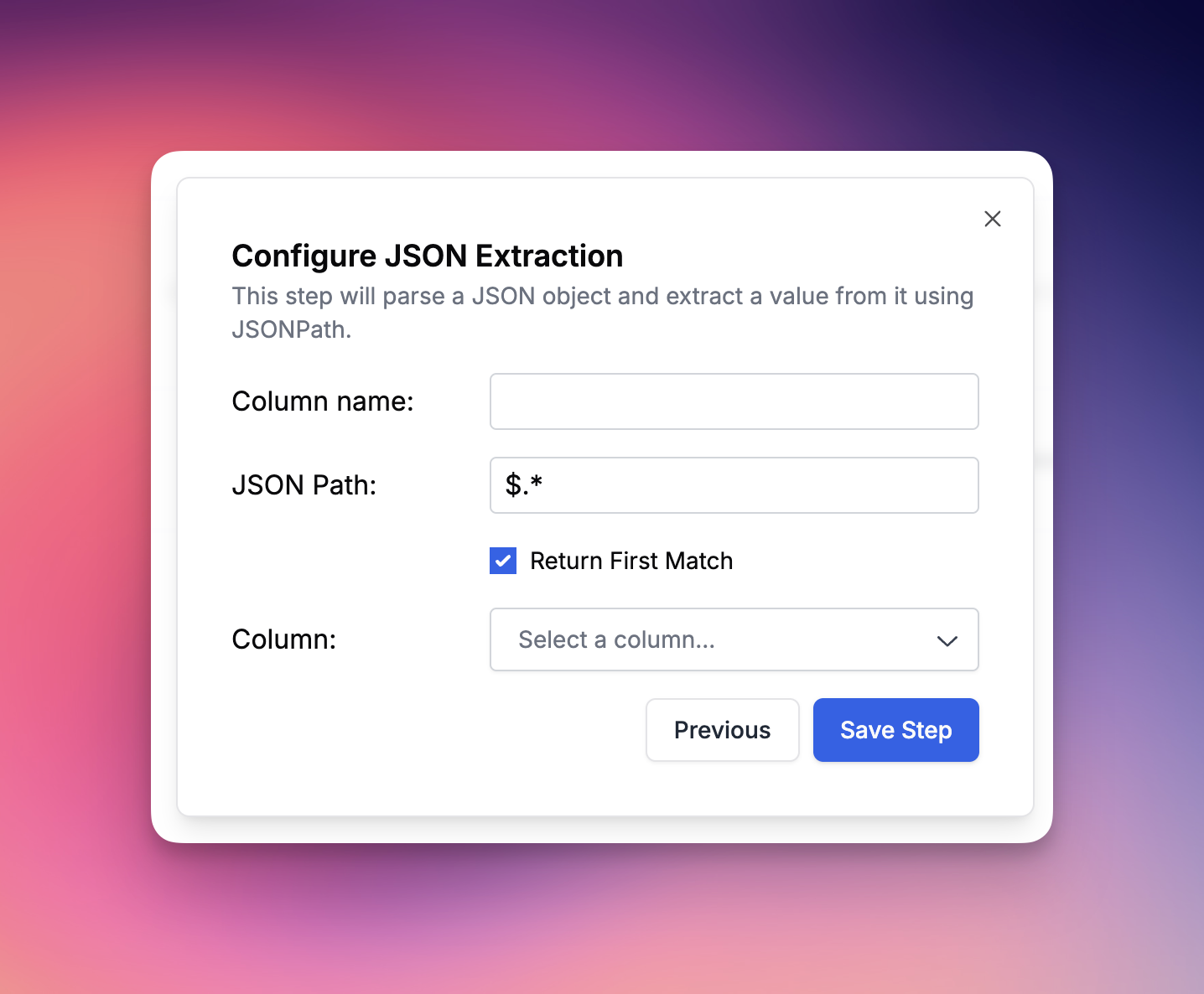
JSON Extraction
The JSON Extraction evaluation type allows you to define a JSON path and extract either the first match or all matches in that path. We will automatically cast the source column into a JSON object. This is particularly useful for parsing structured data within your evaluations.Parse Value
The Parse Value column type enables you to convert another column into one of the following value types: string, number, Boolean, or JSON.Apply Diff
The Apply Diff evaluation type applies diff patches to original content, similar to git merge operations. This helper function requires two source columns: the original content and a diff patch to apply. This evaluation type is particularly powerful when combined with code generation workflows or document editing pipelines where AI agents generate incremental changes rather than complete replacements. It enables sophisticated multi-step workflows where agents can review and refine each other’s outputs. Using diff formats often saves context and leads to better results for editing large content. Diff Format Details The diff patch must be in the standard unified diff format, including file headers and hunk headers, as used by tools likegit and described in the unidiff documentation.
If you are using an LLM to generate the diffs, copy and paste the following text into your prompt for format specifics:
Static Value
The Static Value evaluation type allows you to pre-populate a column with a specific value. This is useful for adding constant values or context that you may need to use later in one of the other columns in your evaluation pipeline.Type Validation
Type Validation returns a boolean for the given source column if it fits one of the specified types. The types supported for validation are JSON, number, or SQL. It will returntrue if the value is valid for the specified type, and false otherwise. For SQL validation, the system utilizes the SQLGlot library.